 华夏名网帮助中心
华夏名网帮助中心导读:4月13日,在英伟达的新品发布会大会上,英伟达 CEO 黄仁勋如期拿出了首款 CPU 芯片 Grace,剑指 AI 云计算。

▲英伟达 CEO 黄仁勋,来源:NVIDIA GTC
英伟达收购 ARM 预示着 N 厂必然进军 CPU 领域,在云计算市场有所作为。
而本次发布会上除了 Grace 之外,英伟达还发布了 Transformers 框架——NVIDIA Megatron;药物研发加速库 Clara Discovery 模型等产品,也侧面印证了笔者的观点,英伟达正在软硬齐发为进军云数据中心领域铺平道路。
无独有偶,上周英特尔也发布了 10nm 的至强三代处理器,在新任 CEO 帕特·基辛格的带领下,英特尔也要加强自身在云计算领域的优势。
不过在这场英特尔对阵英伟达的“双英”大战中,双方的策略明显不同,英特尔注重于全面,除了 AI 以外还在安全、虚拟化及调度能力以及存储性能等等方面全线开花;但是英伟达则在专注于 AI 云及低功耗超级计算机几个重要领域进行定点突破。
虽然目前还无法预测“双英”大战的结局,不过 AI 云计算的发展空间还是有目共睹的。
从最新的 AI 发展趋势来看,最新的人工智能模型对于算力的要求往往都是非常高,比如可以自动写代码的 GPT-3 其参数规模突破了 1000 亿。
而 GPT-3 的变种,可以将文字描述转化为图像的跨模态生成模型 DALL.E,其模型参数数量更是达到了惊人的 1500 亿,不少 AI 方面的科学家指出,越大的模型往往表现更好,扩大规模可能仍然是实现更好性能的方式。
用黄仁勋在发布会上的话来说:
三年间大规模预训练模型的参数量增加了 3000 倍。我们估计在 2023 年会出现 100 万亿参数的模型。
目前资金实力一般的创业公司将越来越难以通过自身的算力去训练最新、最好的 AI 模型。
从另一个角度讲,AI 模型越来越大的趋势也推进了 AI 与云的结合,只有充分发挥云计算降本增效的特性,才能降低门槛,促进 AI 行业创新性发展。也只有做好 AI 云,才能让 AI 充分发挥威力,体现价值。
我们看到本次英伟达围绕着 AI 云计算,在 CPU、智能驾驶及阿配套软件方面同都有不少的进展,接下来,本文将为大家逐一进行解读。
01 Grace 打破内存与显存之间的墙
由于 ARM 使用 RISC 风格的精简指令集, ARM 核心在指令预测等方面同天然比 X86 更有优势,能耗也比 X86 更低。当然这些都是 ARM 相对于 X86 的传统优势,本次 Grace 最大的创新点在于把 CPU 与 GPU 之间的通信速度提升了近 10 倍。根据黄仁勋的说法:
这是一万名工程人员历经几年的研发成果,旨在满足当前世界最先进应用程序的计算需求,其具备的计算性能和吞吐速率是以往任何架构所无法比拟的。

CPU 和 GPU 的通信速度的重要性,可以用苹果 M1 的例子来加以说明。
我们知道苹果 M1 显卡与内存加在一起只有 16 个 G,对比上一代 Mac PRO 内存128G,光是显存都有 16G,不过搭载 M1 的入门版 Mac 在进行图像处理等需要 CPU 与 GPU 进行协同的运算任务时,至少比上一代顶配的 Mac 性能高出近一倍。其中的秘决就是将内存与显卡进行统一管理,从而大大提高了 CPU 与 GPU 的通信效率。
当然苹果将内存与显存混用的做法,在云计算这种多租户共存的场景下并不太适用,但是现有 GPU 与 CPU 共享内存的做法效率确实不佳,在共享内存的方案下,CPU 和 GPU 必须轮流访问内存,这就意味着他们要争夺数据总线的使用权。
因此 GPU 和 CPU 不得不轮流使用一个狭窄的通信管道来做数据交换。而英伟达的 Grace 在这方面做出了突破性的进展。
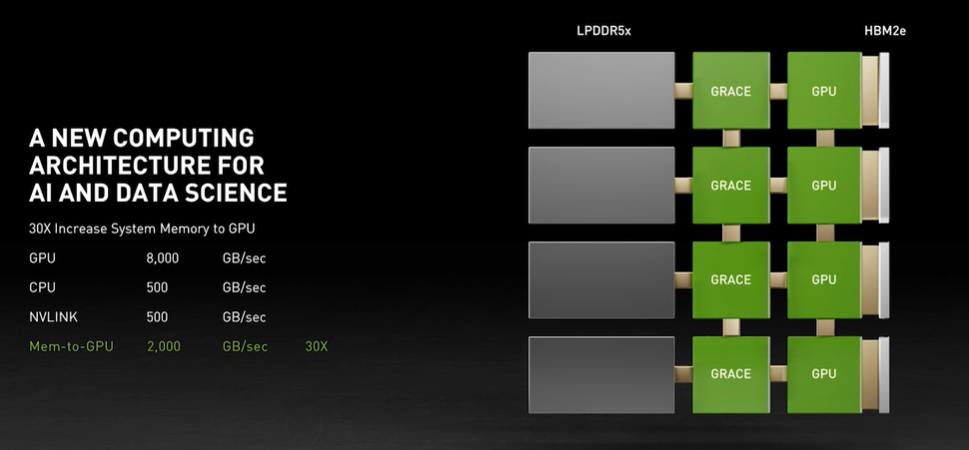
类似于 DMA 控制器在磁盘与内存之间搭建了一条快速通道一样,Grace 体系中 GPU 核心与 CPU 核心之间的通信不需要 CPU 的调度,也不需要占用数据总线的带宽,之前 CPU 必须将数据从其内存的区域复制到 GPU 使用的区域。
而在 Grace 的加持下,CPU 只需要告诉GPU在内存的某位置有 30MB 的向量数据,然后就可以去做其它事了,GPU 则可以通过 Grace 复制通道迅速开始计算任务。
可以说 Grace 的快速能道基本还在笔者的射程范围之内,而英伟达马上要推出的 L5 级别自动驾驶芯片,就只能令人仰望了。
02 英伟达自动驾驶Orin-剑指L5的雄伟蓝图
钢铁侠马斯克上周刚刚宣布特斯拉全新的自动驾驶系统 FSD Beta9.0 已经接近完成,有消息称 FSD 的自动驾驶能力要达到 L5 级,这真是一个震惊世界的消息,因为目前特斯拉的 AutoPilot 还没有达到 L3 的程度。
在业界公认的自动驾驶 L 级分类标准中,依据驾驶任务中 AI 与人类的角色分配以及有无设计运行条件限制等因素,将驾驶自动化分成 0 至 5 级。
- 其中0级为应急辅助级在应急情况下帮助驾驶员进行辅助操作,在 0 级至 2 级自动驾驶中,监测路况并做出反应的任务都由驾驶员和系统共同完成,并需要驾驶员接管动态驾驶任务;
- 3 级为有条件自动驾驶,4 级高度自动驾驶仅在特定条件下需要驾驶员参与;
- 5 级完全自动驾驶的驾驶自动化系统在其设计运行条件内,能够持续地执行全部动态驾驶任务和执行动态驾驶任务接管,驾驶员可以完全退化为乘客的角色。
L5 级别的自动驾驶看似不是从0到1的开创性工作,但从实践上看,想真正实现全天候的自动驾驶难度极大。从谷歌的公开资料中我们可以知道一台自动驾驶测试车辆每天至少会产生10T的数据量,平均每分钟都要处理几百M的数据。
而且自动驾驶的决策延时必须要控制得极低,汽车以80公里/小时的速度运行时其机械制动距离就接近30米,想保证安全留给自动驾驶的反应时间通常只有0.1秒,而且作何一点决策上的失误都可能造成极其严重的后果。
简单说 L5 级别的自动驾驶是一个每秒数据处理能力 1 个 G,数据处理延时不能超过0.1s,而且可靠性还不能低于 99.999999% 的极精密系统,再考虑其 AI 模型的上百亿个参数,这个系统对于算力的要求是十分惊人的,不过更惊人的是黄仁勋表示英伟达就是要干这个。
根据计划,英伟达将于 2022 年投产支持 L5 自动驾驶的汽车计算系统级芯片NVIDIA DRIVE Orin,与此同时英伟达还在发布会上展示了搭载 3 个 Orin 核心的 Hyperion 8 自动驾驶汽车平台。
据称 Hyperion 8 是业内算力最强的自动驾驶汽车模板,当然这款芯片目前还没有量产,也没有具体细节的发布,因此笔者这里只能先对英伟达表示 Respect。
03 AI 软件的背后:感知智能向认知智能的演进
从实现快速计算、记忆与存储的“计算智能”,到识别处理语音、图像、视频的“感知智能”,再到实现思考、理解、推理和解释的“认知智能”,人工智能发展的终极目标是赋予机器人类的智慧。
近年来,语音识别、人脸识别等“感知智能”技术已相对成熟,甚至在许多领域已经达到或超出了人类的水平。但这些技术仅在工具、模型层面实现了突破,对诸如需要专家知识、逻辑推理或者领域迁移等需要去思考、规划、联想、创作的复杂任务时,表现不佳。
不过随着大数据、云计算、深度学习等技术的蓬勃发展,探索在如何保持大数据智能优势的同时,赋予机器常识和因果逻辑推理能力,实现“认知智能”,成为当下人工智能研究的核心。
从人机协作的角度上看,人类在处理抽象化、情绪化、非逻辑性的问题上有着不可逾越的优势,而大量重复、海量计算和海量记忆则是人工智能的强项。
而AI目前一个重要的发展方向就是让人机两者的强项联合,取长补短,比如金融行业的呼叫中心需要分析客户的语气,在必要时引入人工服务;出行类 APP 遇到客户说出某些关键词时,则需要立刻与 110 人工报警台联动报警。
这样的大趋势下也就更需要 AI 由单纯的感知世界向认知世界去进行升级。我们看到阿里、腾讯的论文,近年来在 KDD 及 CVPR 这样的 AI 顶会上获得不俗的成绩,多半也是源于对于认知智能的突破性贡献,而英伟达本次推出的与 AI 系统对应的配套软件中也顺应了这一潮流。
本次发布的 Transformers 训练框架 NVIDIA Megatron、Morpheus 数据中心安全平台、新一代人工智能对话机器人 NVIDIA Jarvis、推荐系统是 NVIDIA Merlin、隐私保护加强的 AI 辅助套件 NVIDIA TAO,从本质上讲都是认知智能的一种体现。
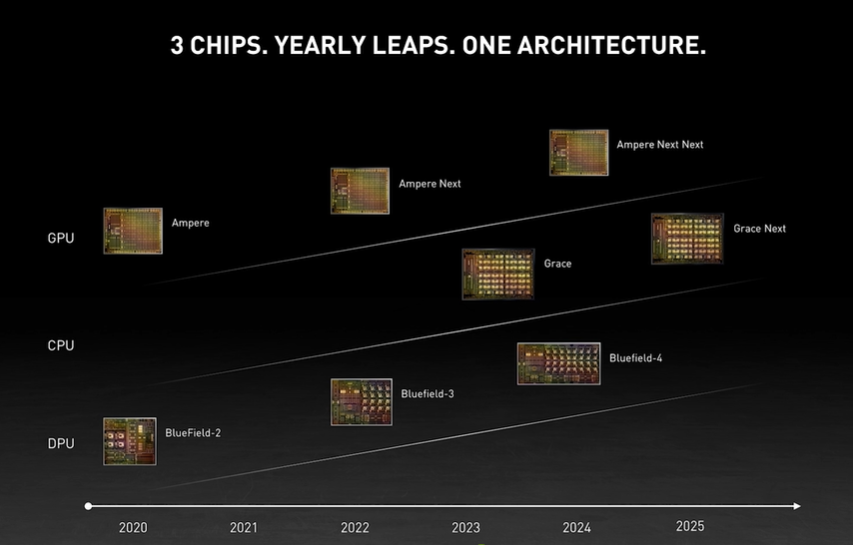
纵观整场发布会,英伟达真可谓是 AI 与智能驾驶齐飞,CPU 与 GPU 跨界。新时代的计算机需要新的芯片、新的系统架构、新的网络、新的软件和工具。英伟达全新的数据中心路线图已包括 CPU、GPU 和 DPU 三类芯片,将英伟达也将被重新定义为三芯片公司。
【免责声明】
本站系本网编辑转载,转载目的在于传递更多信息,并不用于任何商业目的。文章版权归原作者及原出处所有,内容为原作者个人观点,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时与本网联系,我们将在第一时间删除内容!本站拥有对此声明的最终解释权。
